A whole new world model
One of the most inspiring moments of the last few months was the Artemis II voyage around the moon. Space: cool, the astronauts: cool, a solar eclipse from the other side of the moon: very cool.
Also cool: using the moon itself as part of the return home. As folks who'd watched Apollo 13 already knew, the moon's gravity could be used in conjunction with Earth's own gravity to pull the rocket back down to the blue marble. That big floating orb of cheese could be used as a corrective, a steer. An extra force of gravity being used in conjunction with another.
If you’ve played with LLMs before, even just tweaking a system prompt, Artemis II’s ‘gravity slingshot’ trick might resonate as a metaphor. Working with language models, – particularly less powerful ones, and particularly on niche topics – you can feel the gravity of the model’s training pulling sentences back to its mass.
This isn't always a problem if what you're doing is just supplying a list of steps to follow or integrating up-to-date information, but it can be a real pain on some tasks. The companies creating the LLMs are certainly aware of it, aware of the need for something to help course-correct the gravitational pull of the model's linguistic weights. Enter: ‘world models’.
If you want an ‘explain it like I’m 5’ intro to world models, you could say that while LLMs understand lots of words, they only understand things like 'gravity' based on what they’ve read about it, and not the actual effects that you tend to learn by spending formative months as a toddler dropping things from your high chair. The Big Tech companies think that by injecting world models into the system, this will act as a moon to the LLM's Earth.
Being a dork who writes analytics blogs, I'd heard folks talk about this months ago, but earlier this week I had an apple-falling-on-the-head moment.
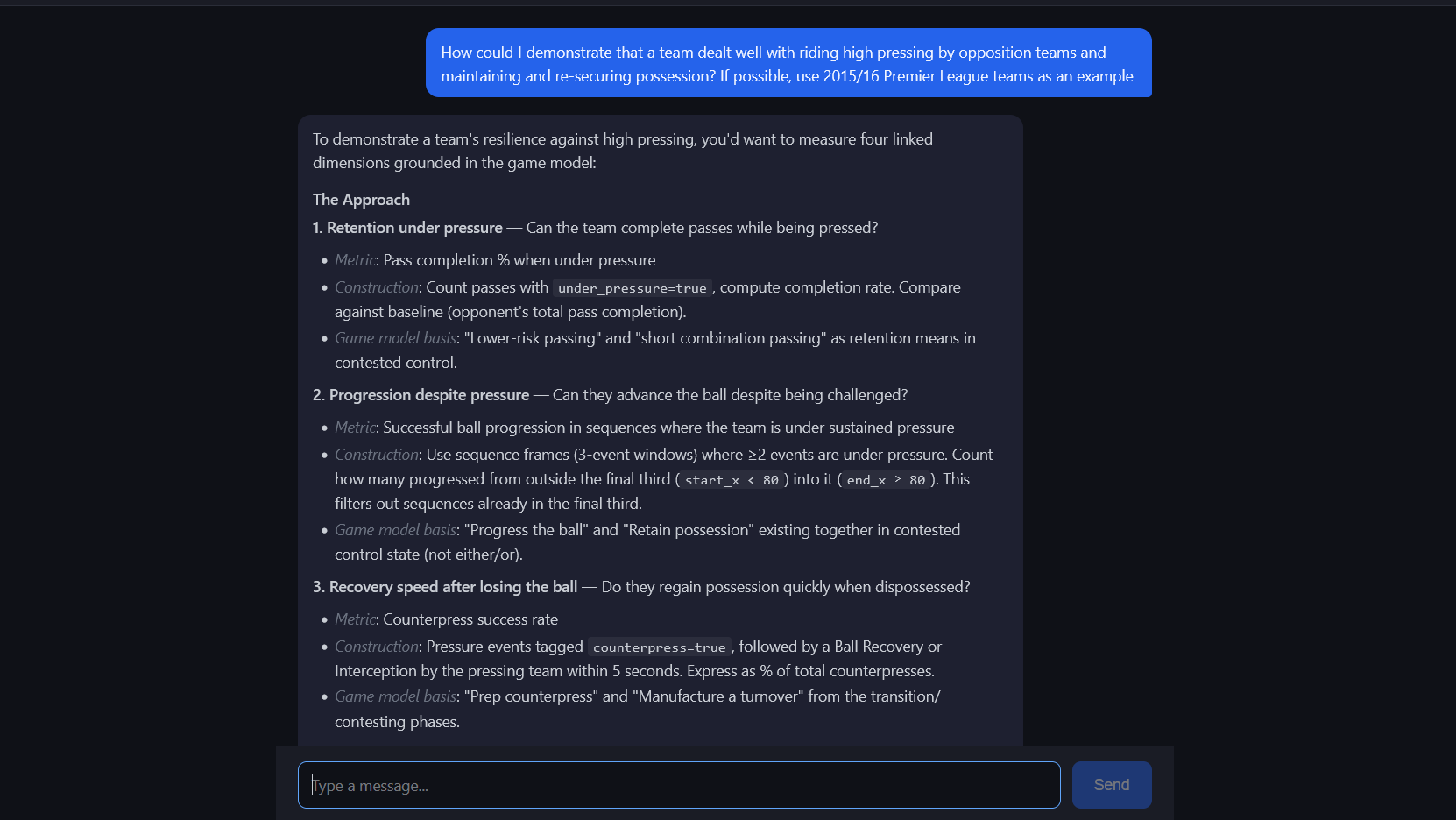
There’s a project I’ve been working on – which I'll talk a bit about in a moment – which relates to these concepts. The project brings together a few strands I’ve been interested in: language models, constructing things from event data, and how coaches can be better helped in bringing their ideas about the game to life.
I set about building an LLM agent that can pull in a coach’s game model, pull in information about available football data, and work some magic. 'Working some magic' is easy; 'working a little bit more than some magic, a little bit more than some of the time' is harder.
One of the problems, as it turns out, is that the language models I was experimenting with weren’t able to work out how to do complex things with event data just from first principles and some provider docs. (As I tend to, I was of course using the Statsbomb open dataset; my comment here is no shade on their docs, they’re better-suited to this than some competitor provider docs might have been)
So, not only did I have to add a rough version of a coach's game model to the system (which I wrote), I needed to add extra help to the system around how to work with event data. I did that, it helped things, and then, listening to a podcast where Big Tech’s world models came up, it hit me: that's what I'd been doing. I'd been adding a form of world model to the system. A coach/analyst-style 'game model' is just a world model for a specific type of world.
Here's the video:
One of the unexpectedly interesting parts of the project is that the Anthropic models have clearly been reading Inverting the Pyramid and Spielverlagerung. Tactical questions to the Claude web app get surprisingly convincing responses, terms like 'mid block' and 'pressing triggers' readily spring into its responses. In some areas, the web app would probably do better than my hobby project agent; although it obviously wouldn’t be able to call on the specific Statsbomb data it’s integrated with.
It should be said: LLM development is still a pretty terrible experience, and should turn any developer into a unit test-appreciator. Not only are the results non-deterministic, but if you’re cost-conscious (which, on a hobby project, I definitely am) then every test involves throwing Anthropic a non-deterministic fraction of a dollar. It used to be the case that the advice was to build with a powerful model, and then refine and compress efficiency into a smaller model once you had something working. I’m wondering now, as the trajectory of local-runnable models continues, whether the reverse would be true now: prototype with more limited models, then get a performance boost when you switch to a costly model from an LLM provider.
It’s partly for this reason that I don’t have evals for this system (but partly also because that’s an extra set of work that isn’t really needed). It’s been enough to just look at the results and scrutinise logs in Langsmith.
A special side-effect feature of this project has been a pay-off for the wonkish theory blogs written over the years, like this about phases and forms of control. It’s easier for agent tool purposes if the game model is semi-structured, and all that past thinking helped inform the structure. It only lightly affects the conversation about England’s press in 2023, but comes through more with questions like this:
Is this the "Claude AI-morim" that I riffed on back in January? No, obviously. Is it close? Ish.
One of the interesting things with agentic systems is the way that capability and testing requirements scale in completely different ways to 1) how they would in conventional systems 2) each other.
Imagine the user flows of traditional software like a set of rectangular corridors that you create. Each door in the corridor represents an action a user can take, and as you add more features, more corridors can be walked down. If you tested that system, you'd need more tests than features, because the corridor has more to it than just the doorways.
Dealing with an LLM agent is like if that same 'corridor as software feature' idea was switched so that corridors were no longer rectangles, but fractal shapes, like three-dimensional snowflakes. There will be more doors, and doors in better places and more interesting angles, but the surface area of the entire structure increases at a much higher rate than the number of doors.
This, after all, is why you still see so many laughable screenshots of Google's AI overviews. The sheer infinite variety of things people can type into a search box is more, by degrees of magnitude, than a non-deterministic system can deal with (without heavy guardrails).
Maybe a different type of world model, based around user intent and propensity to mischief, is something Big Tech needs to think about. Another gravitational steer for the LLMs, this time away from farce. As I'm sure the Artemis II crew said just before doing their lunar fly-by: 'what a world'.